Podevcast: A single source for developer podcasts
Developer podcast from a single place, a podcast player static site generated using Python : Netlify x Hashnode Hackathon

I am a Student, self-taught web programmer, Linux and Vim Enthusiast. I like to try out and experiment with new technologies and programming languages.
Introduction
Hello Developers! Want to listen to programming podcasts from a single place? Podevcast is the place you should be searching for.
I am Meet Gor and I present this project as a submission to the Netlify x Hashnode Hackathon. Podevcast is a webpage(static) for listening to podcasts centered around developers and programming. Just pick your favorite one and start listening straight away. Let's dive into the making of Podevcast. Head on to https://podevcast.netlify.app/ to check out the live app.
What is Podevcast
Podevcast is a web application or a static site that renders the top programming/development podcasts. You can listen to the top podcasts around the developer community from a single source.
Listen to your favorite developer podcasts with Podevcast
Podevcast is a static site generated using a script. There is a static site generator that is heavily done in Python and deployed to Netlify. You can simply listen to the podcasts on the web page or go to the canonical page of the podcast episode. From the canonical page, you can choose to hop to your chosen music player, but the default music player should be fine for casual listening. The core idea is to keep things in a single place for developer podcasts.
Preview
Podevcast has popular developer podcasts like Command Line Heroes, The Python Podcast, The freeCodeCamp Podcast, and many others to choose from. You can go into categories for looking at a specific podcast.
Application Demonstration
Here's a small demonstration of the Podevcast application.

Podevcast has multiple pages like:
The Home page has the latest episode of all the podcasts. It also has an audio player to play on the go.

The Podcast List page has the list of all the Podcasts available in the project. It has the name of the podcast with the link to the podcast page that has the list of all the episodes of that podcast.

The categories page has a list of categories of the podcasts like Web-development, backend, frontend, data science, DevOps, and so on. More categories will be added soon.

The Episode page has the audio player, the summary of the episode, canonical episode, and podcast page.

Why Podevcast?
Listening to music is one thing and listening to podcasts is different. I wanted a place from where developers can listen to developer-specific podcasts from a single source not just give out the article "Top 10 podcast you should be listening to as a developer". Having played around with python and some libraries like feedparser and jinga previously I saw this Hackathon as an opportunity to convert the idea into a project. It fits the JAMStack area well from the Hackathon and project perspective.
Tech Stack
- Python
- GitHub Actions
- HTML / CSS
The data is extracted from various RSS Feeds using the feedparser library in Python.
Using GitHub Actions, the feed is refreshed every 24 hours to fetch the latest episodes from the respective podcast feeds. Basically, the GitHub action triggers a Netlify deployment that in turn generates the static site by running the script.
The command for running the script on Netlify and generating the Podevcast webpage is :
pip install -r rquirements.txt && python script.py
And the directory for deployed web pages (published directory) is site which contains all the HTML files that can be rendered as the website itself.
Source Code
The project is available on GitHub. Feel free to open a PR to add a Podcast or a Category. The project only has a few python files, the main script is script.py which actually creates the home and the podcast list pages along with the episode pages. The src folder contains some extra bits of scripts like creating the categories and category podcast list pages. Also, it has certain config files like runtime.txt, requirements.txt, and so on. Finally, there is the podlist.json for the list of podcasts and categorylist.json for the categories of podcasts.
Core Script Snippet
The python script looks a lot bigger than the below snippet but it is doing the same process multiple times for different pages. There is also some type checking and tiny details that are added as per the requirement of the templates.
import feedparser
from jinja2 import Environment, FileSystemLoader
from pathlib import Path
template_env = Environment(loader=FileSystemLoader(searchpath='./layouts/'))
index_template = template_env.get_template('index.html')
episode_template = template_env.get_template('episode.html')
feed = feedparser.parse("https://freecodecamp.libsyn.com/rss")
pod_name = feed['feed']['title']
for i in range(0, len(feed['entries']):
ep_title = feed['entries'][i]['title']
audio = feed['entries'][i]['links'][1]['href']
cover_image = feed['entries'][i]['image']['href']
og_link = feed['entries'][i]['links'][0]['href']
episode_obj = {}
episode_obj['title'] = ep_title
episode_obj['audiolink'] = audio
episode_obj['cover'] = cover_image
episode_obj['link'] = og_link
with open(os.path.join(f"site/{pod_name}/ep/{i}/index.html"), 'w', encoding='utf-8
ep_file.write(
episode_template.render(
episode = episode_obj
)
)
Above is a simple snippet of the core functionality of the script. It basically takes the RSS Feed URL of the podcast and using feedparser the data is retrieved in the form of a dictionary in Python.
- Iterate over the
feed['entries']which is a list of lengths same as the number of episodes of that podcast, we then assign a set of values likeepisode title,audio link,cover image,canonical link for the episode,dateand so on. - Create a dictionary and store the key value as the mentioned data to access from the template.
- Open a file in the structured file format and then parse the
episode_objwhich is a dictionary to the episode template. - Access the dictionary using jinga2 templating tags.
<html>
<head>
<title>Podevcast</title>
</head>
<body>
<h3 class="ep-title">{{ episode.title }}</h3>
<img src="{{ episode.cover }}">
<a class="ep-link" href="{{ episode.link }}">Episode </a>
<audio controls="enabled" preload="none">
<source src="{{ episode.audiolink }}" type="audio/mpeg">
</audio>
</body>
</html>
We can use {{ }} to access any value parsed to the template via the script. Also, we can make use of {% %} to run loops, conditionals, blocks, and other tags in the template.
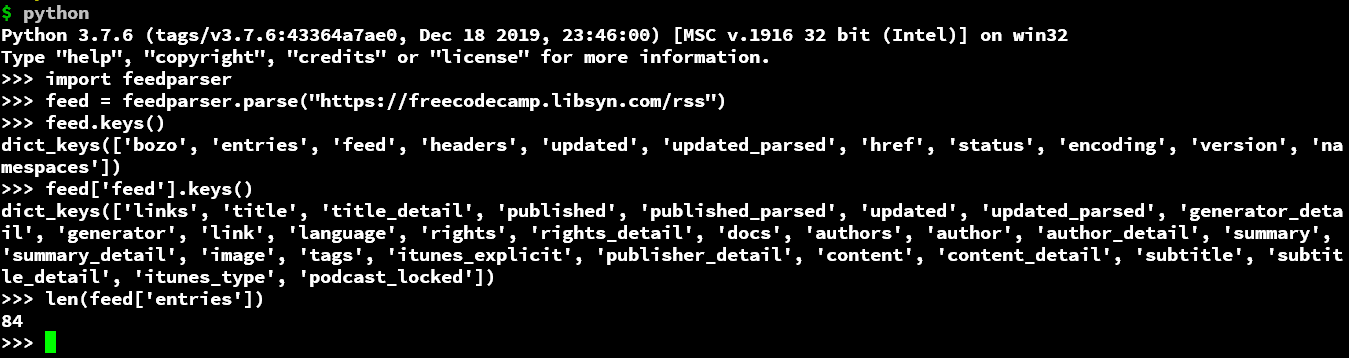
So, we can see the feed is basically a dictionary that has a key-value pair and further, it can be a nested dictionary or a list as a value of a key. As in the case of feed['entries'] is a list with the length of the number of episodes of a podcast. And in the script, we use various keys to access various components, obviously, this requires a bit of exploration of the dictionary initially but it becomes easy thereafter to automate using Python.
Episode List
Currently, the episodes are added using the JSON file. It is not that user-friendly but still not a big task to simply add a link in a file. This is a #TODO that will require some external tooling to integrate into the webpage to ask for a form to submit a new Podcast.
{
"Command Line Heroes": "https://feeds.pacific-content.com/commandlineheroes",
"Python Podcast__init__": "https://www.pythonpodcast.com/feed/mp3/",
"Real Python Podcast": "https://realpython.com/podcasts/rpp/feed",
"The freeCodeCamp Podcast": "https://freecodecamp.libsyn.com/rss",
"CodeNewbie": "http://feeds.codenewbie.org/cnpodcast.xml",
"Linux For Everyone": "https://feeds.fireside.fm/linuxforeveryone/rss",
"JavaScript Jabber" : "https://feeds.fireside.fm/javascriptjabber/rss"
}
The process requires a manual test to validate a given RSS Feed as not all feeds are generated the same way and thus there are a few exceptions that need to be sorted out manually. For example, the Python Podcast doesn't have a cover image parsed into the RSS Feed, so there needs to be a check for it in the script and also in the template to restrict parsing and displaying the cover image link.
Episode Categories
This is also a JSON file that holds the keys as the category and the value as a list of episode names (strictly the name from feed['feed']['title']). There needs to be a human decision to be taken to add the podcast into a specific category.
{
"Python":[
"Talk Python To Me",
"The Python Podcast.__init__",
"The Real Python Podcast",
"Python Bytes"
],
"Javascript":[
"Full Stack Radio",
"JavaScript Jabber"
],
"Linux":[
"Command Line Heroes",
"LINUX Unplugged",
"The Linux Cast",
"Linux For Everyone"
],
"Data Science":[
"DataFramed",
"Data Skeptic",
"The Banana Data Podcast"
]
}
Though the JSON file is managed manually the generation of the categories is automated. Please feel to add other categories of your choice.
What's Coming?
Certain features like adding podcast using a form, adding more podcasts, and categories for sure. Though what looks a bit cloudy in my opinion is adding accessibility links to music players because the RSS feed doesn't contain direct links to them. Though I still to explore and find out if it can be obtained from the feed itself.
Search box for searching podcastsTheme Toggle (Light/Dark)- Accessible Links to other platforms (Spotify, Itunes, etc)
- More depth in categories (Languages/Frameworks/Niche-specific podcasts)
I'll add these features after checking the feasibility of the ideas and the response from the community after releasing them.
Final Words
This project wouldn't have existed without this Hackathon as it gives a deadline to finish and hope to win something. Specially thanks to Hashnode and Netlify for organizing such a great opportunity in the form of a hackathon. Also, the maintainers of Python libraries like feedparser and jinja. The project would have been impossible without them.
If you like the project please give it a star on GitHub. Have any feedback? Please let me know in the comments or on Twitter. Thank you for reading, Hope you have a good time using Podevcast. Happy Coding :)




